


2010-04-28 00:00
Autor: Sebastian Wiśniewski (NetCop)
62
GeForce GTX 480 i GTX 470 - karty DX11 od NVIDII
Strona 2 - Architektura GF100
Architektura układu GF100
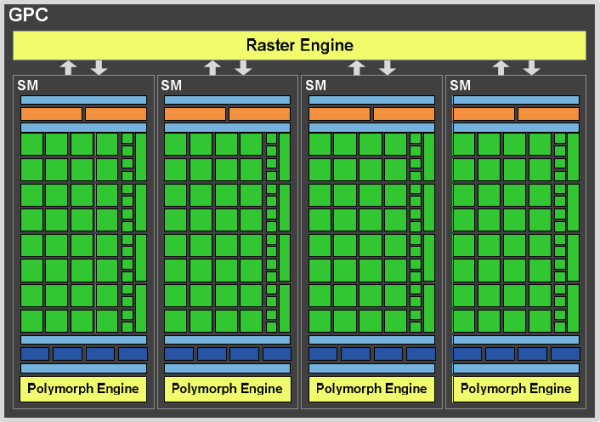
GPC
Na początku wspomniałem, że układ GF100 składa się z czterech klastrów przetwarzania grafiki:
ROP
Wewnątrz bloku oznaczonego na powyższym obrazku jako Raster Engine znajduje się 8 jednostek ROP. Są one przypisane do klastra, a także usprawnione. Przede wszystkim poprawie uległ tryb wygładzania 8xMSAA i nie jest on już tak mocno obniżający wydajność jak to miało miejsce w układzie GT200.
![]()
Blok SM
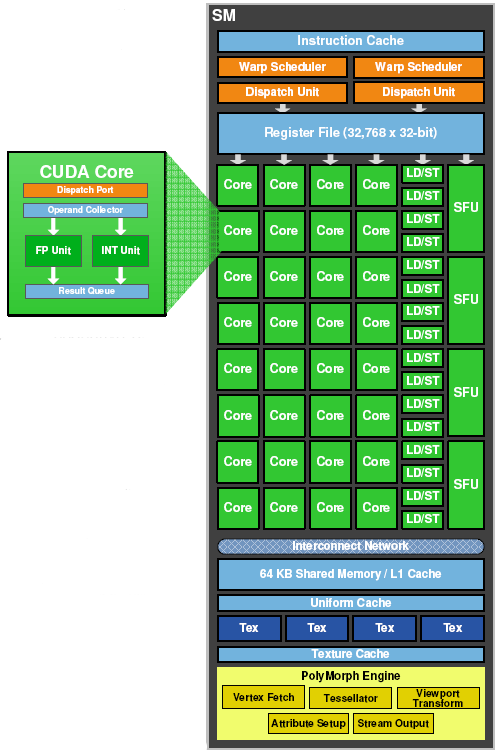
Jednostki teksturujące
Nowością jest przeniesienie jednostek teksturujących do wnętrza bloku SM. Dzięki takiemu zabiegowi pracują one teraz z wyższym taktowaniem, takim samym jak dla procesorów strumieniowych.
Polymorph Engine
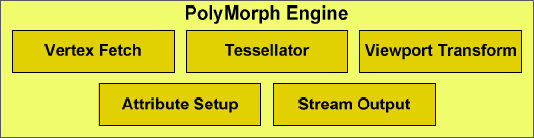
Przy takie budowie układu GF100 teselacja staje się konikiem NVIDII, z tego względu, że konkurencja może pochwalić się jedynie dwoma jednostkami odpowiadającymi za teselację znajdującymi się w układzie Cypress.
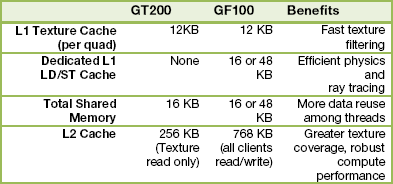
Cache L2
Układ GF100 posiada znacznie więcej pamięci cache drugiego poziomu niż GT200. Będzie wpływało to korzystnie na szybkość obliczeń. NVIDIA podaje konkretnie na jaki zysk możemy liczyć.
"ECC everywhere"
Fermi, projektowany z myślą o zaawansowanych obliczeniach GPGPU z 64 bitową precyzją musi dbać o jakość tych obliczeń. Po raz pierwszy mamy do czynienia z sytuacją, gdzie wszystko chronione jest przez mechanizmy ECC. Przez wszystko rozumiem wszelką pamięć, zarówno RAM jak i cache L1 i L2, a także rejestry. ECC nie specjalnie przyda się jednak graczom.